통계적 추론의 분류
| 분류 기준 | 통계적 추론 | |
| 분포 가정 유무에 따른 분류 |
모수적 추론 = 모수 통계 (Parametric Inference) |
모집단에 대해서 특정 분포를 가정하고, 그 분포를 결정하는 모수에 대해 추론하는 방법 모수 검정 방법: t검정, 분산분석, 회귀분석 등 |
| 비모수적 추론 = 비모수 통계 (Non-Parametric Inference) |
모집단에 대해 특정한 분포를 가정하지 않고, 주로 이상값이 존재할 때 사용 비모수 검정 방법: 콜모고로프-스미르노프, 윌콕슨 부호 순위 검정, 맨-휘트니U |
|
| 모수 처리방식에 따른 분류 |
빈도론자 추론 (Frequentist Inference) |
모수를 고정된 값인 상수라고 가정 |
| 베이지안 추론 (Bayesian Inference) |
미지의 값(모수, 결측값, 미래값)을 확률변수라고 가정하고, 해당 확률변수의 확률분포에 관심을 가지는 것 | |
| 추론 목적에 따른 분류 |
추정(Estimation) | 표본의 통계량을 이용하여 모집단의 모수의 근사값을 결정하는 방법 |
| 가설 검정 (Testing Hypotheses) |
모집단에 대한 가설을 나름대로 세워 그 가설의 옳고 그름을 확률적으로 판정 |
추정의 종류
| 분류 기준 | 점추정 | 구간추정 |
| 목적 | 표본자료를 이용하여 모수의 참값이라고 추정되는 하나의 값을 결정 | 모수의 참값이 포함되어 있으리라고 추정되는 구간을 결정 |
| 관심사 | 모평균 μ의 참값이라고 추정되는 하나의 값을 어떻게 결정할 것인가 | 모평균 μ의 참값이 포함되어 있으리라고 추정되는 구간을 어떻게 결정할 수 있는가 |
| 예 | 가구 평균 대출금액은 5천만원이다. | 가구 평균 대출금액은 5천만원 ±500만원이다. |
모수, 추정량, 추정값의 의미
| 구분 | 설명 |
| 모수 | 모집단을 요약/설명해주는 기술 통계 도구 모평균, 모분산, 모비율 등 |
| 추정량 | 모수 θ의 값을 추정하기 위해 이용되는 통계량 표본을 이루는 확률변수들의 함수, 하나의 확률변수 표본평균, 표본분산, 중앙값, 최대값, 최소값 등 |
| 추정값 | 추출된 특정 표본값에 의해 계산된 추정량의 값(점추정값) 추정치라고도 함 |
추정량과 추정값

추정량의 4가지 준거

*'불편'은 추정의 편향(Bias)이 0인 추정량이기도 하다.
모평균, 모비율, 모분산의 점추정

점추정 방법

구간추정의 정의
| 구분 | 설명 | 기호 |
| 신뢰계수 (Confidence Coefficient) |
모수 θ의 참값이 포함되어 있으리라는 확신의 정도를 나타내는 측도 1 - α = 0.99, 0.95, 0.90 |
1 - α |
| 신뢰수준 (Confidence Level) |
모수가 어느 범위 안에 있는지를 확률적으로 보여주는 방법 | (1 - α) x 100% |
| 신뢰구간 (Confidence Interval) |
특정 확률을 가지고 모집단의 모수가 포함될 것으로 예견되는 구간을 표본으로부터 도출한 범위의 값 구간추정치(Interval Estimate)이라고도 함 |
신뢰하한: LCL 신뢰상한: UCL LCL: Lower Confidence Level UCL: Upper Confidence Level |
| 유의수준 (Significance Level) |
표본을 추출하여 모평균에 대한 구간추정을 함에 있어서 발생되는 오차에 대한 허용범위 유의수준 α = 0.01, 0.05, 0.1 등 |
α |
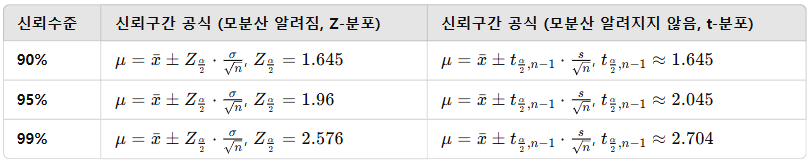
모평균의 신뢰구간 추정
1. 모분산이 알려져 있을 때 (정규분포 사용)

2. 모분산이 알려지지 않았을 때 (t-분포 사용)

신뢰구간 공식
모비율의 신뢰구간 추정


모분산의 신뢰구간 추정
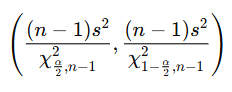

두 모분산비의 신뢰구간 추정


가설의 종류

통계적 가설 검정
| 구분 | 설명 |
| 검정통계량(T(X)) | 귀무가설과 대립가설 중에서 하나의 가설을 선택하는데 사용하는 표본의 통계량 검정통계량: Z통계량, t통계량, 카이제곱통계량, F통계량의 확률분포상 x축 좌표값 |
| 기각역(C) | 가설 검정에서 유의수준 α가 정해졌을 때, 검정통계량의 분포에서 이 유의수준의 크기에 해당하는 영역 검정통계량의 분포에서 이 영역의 위치는 대립가설의 형태에 따라 다름(귀무가설 기각) |
| 채택역(A) | 가설 검정에서 유의수준 α가 정해졌을 때, 검정통계량의 분포에서 이 유의수준을 제외하는 크기에 해당하는 영역 채택되는 검정통계량의 영역(귀무가설 채택) |
통계적 가설 검정 절차
| 구분 | 설명 | |
| 1단계 | 가설 설정: 귀무가설 및 대립가설 설정 대립가설에 따라 단측검정 혹은 양측검정 방법 선택 |
|
| 2단계 | 유의수준(α) 결정: 제 1종오류를 범할 위험의 최대값을 제한 | |
| 3단계 | 검정통계량 선정 및 계산 | |
| 기각역 사용 (가설 검정) |
4단계 | 표본크기 n과 유의수준에 따른 기각역 설정 |
| 5단계 | 통계적 결론: 검정통계량이 기각역에 속하면 귀무가설 기각, 아닌 경우 귀무가설을 기각하지 않음(대립가설 채택) | |
| P갑 사용 (유의성 검정) |
4단계 | 검정통계량을 사용하여 P값 산출 |
| 5단계 | 통계적 결론: 유의수준이 P값보다 크면 귀무가설 기각, 아닌 경우 귀무가설을 기각하지 않음 | |
'빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 분석 절차 수립 (0) | 2025.03.06 |
|---|---|
| [빅데이터분석기사 필기] 추론통계 출제예상문제 오답노트 (1) | 2025.03.05 |
| [빅데이터분석기사 필기] 기술통계 출제예상문제 오답노트 (0) | 2025.03.04 |
| [빅데이터분석기사 필기] 기술통계(3) (0) | 2025.03.04 |
| [빅데이터분석기사 필기] 기술통계(2) (0) | 2025.03.03 |